Shi-Qi et al.
16 Feb 2024
Introduction
기존의 RAG 프레임워크에서는 retriever에서 검색된 문서의 정확도에 따라서 generation의 퀄리티가 심하게 의존적이라는 위험한 문제가 있었습니다. 저퀄리티의 retriever가 질문과 관련이 없는 정보를 넘겨주면, generator의 퀄리티와 뛰어나더라도 hallucination과 같은 문제들을 일으켜 불만족스러운 response를 출력할 수 있습니다.
따라서 Corrective Retrieval Augmented Generation(CRAG)은 retriever의 출력을 스스로 수정하여 검색되는 문서들의 퀄리티를 향상시킴으로써, generation의 robustness를 강화하고자 합니다. 또한 검색된 문서들이 모두 잘못되었을 경우, web search를 통해 external knowledge에 접근하는 방식을 제안합니다.
CRAG
Retriever로부터 입력 쿼리 X와 retrieved documents가 주어지면, 먼저 1) Retrieval Evaluator가 query-documents의 relevance score를 계산합니다. 그리고 2) relevance score에 따라서 3개의 액션 {Correct, Ambiguous, Incorrect}을 트리거합니다.
- Correct 액션이 트리거되면, retrieved documents를 더 정확한 지식 조각들로 재구성합니다. 재구성은 decomposition-filtering-recomposition 으로 진행됩니다.
- Incorrect 액션이 트리거되면, retrieved documents는 버려집니다. 대신, web search를 통해 관련된 웹 지식 소스를 불러옵니다.
- Ambiguous 액션이 트리거되면, 위 액션들을 결합합니다.

Retriever Evaluator
Retriever Evaluator의 정확도는 이후 프로세스의 결과에 영향을 미치기 때문에 전체 시스템 성능을 형성하는 데 중추적인 역할을 합니다. Retriever Evaluator는 pre-trained lightweight T5-large (0.77B) 모델을 파인튜닝하여 구축되었고, 파인튜닝을 위한 relevant signals는 기존 데이터셋으로부터 수집되었습니다.
우선, CRAG의 retriever가 모든 질문들에 대해서 10개의 문서를 검색합니다. 질문은 입력으로서 각 문서에 합쳐지고, 각 question-document 쌍에 대해 evaluator가 독립적으로 relevance score를 계산합니다. 계산된 relevence score를 기반으로 Action Trigger가 검색이 맞는 지 틀린 지를 최종적으로 판단합니다.
Action Trigger
관련없는 문서를 수정하고, 최종 검색문서를 필요에 따라 재정의하기 위해서, actions는 차별적으로 실행해야만 합니다. 앞서 각 검색된 문서에 대해 evaluator가 계산한 relevance score를 기반으로, upper threshold와 lower threshold의 설정에 따라 3개의 액션 {Correct, Incorrect, Ambiguous}을 트리거합니다. 각 검색된 문서들은 개별적으로 처리되고 통합됩니다.
Evaluator는 각 문서에 대해 -1(negative)로부터 1(positive)까지의 relevance를 점수로 매깁니다. 세 가지 액션 중 하나를 트리거하기 위한 두 임계값은 경험적으로 설정되었습니다. PopQA에서는 (0.59, -0.99), PubQA와 ArcChallenge에서는 (0.5, -0.91), Biography에서는 (0.95, -0.91)로 설정되었습니다.
- Correct
검색된 문서 중 적어도 하나의 confidence score가 upper threshold보다 높으면, 검색을 correct라 가정합니다. 그 말인 즉슨, 검색된 결과들에서 관련 문서가 있다는 것을 의미합니다. 또한 관련있는 문서가 있을 때에도 문서 속에 불가피하게 노이지한 지식이 포함되어 있음을 뜻합니다. 따라서 검색된 문서 속에서 중요한 지식 조각은 추출하고 관련없는 지식은 필터링하기 위해 Knowledge Refinement 방법을 제안하여 적용합니다.
Knowledge Refinement 방법은 decompostion-filtering-recomposition 과정으로 이루어지며, 더 중요한 지식 조각들을 추출하도록 합니다. 검색된 결과가 한 문장 혹은 두 문장 정도로 짧으면 개별 조각으로써 여겨지지만, 그렇지 않다면 검색된 문서를 전체 길이에 따라서 몇 문장으로 구성되는 더 작은 단위로 휴리스틱 규칙을 통해 분할(decompostion)합니다. 각 스케일은 독립적인 정보를 포함한다고 가정하고 필터링은 세그먼트를 기반으로 합니다. 지식 조각 필터링을 위해 앞서 retriever evaluator를 다시 이용하여 각 지식 조각의 relevance score를 계산합니다. 이 score를 기반으로 관련없는 지식 조각들은 필터링되고(filtering), 관련있는 지식 조각들은 internal knowledge로서 결합되면서 재구성(recomposition)됩니다. 논문에서는 top-k는 5, filter threshold는 -0.5로 설정하였습니다.
- Incorrect
모든 검색된 문서의 confidence score가 lower threshold보다 낮으면, 검색을 Incorrect라 가정합니다. 이는 모든 검색된 문서들이 다 관련없고 generation에 도움이 되지 않는다는 것을 의미하므로, 수정을 위해 새로운 지식 소스를 찾을 필요가 있습니다. 따라서 이 경우에는 인터넷으로부터 검색하는 web search 방법을 이용합니다.
Web search 방법은 검색 엔진을 사용하는 우리들의 일상을 모방하기 위해서, ChatGPT를 사용하여 키워드로 구성된 쿼리로 재작성됩니다. 아래 그림은 키워드를 추출하기 위한 프롬프트입니다.

CRAG에서는 공개적이고 접근 가능한 상용 web search API를 이용해서, 모든 쿼리에 대한 URL 링크를 생성합니다. URL 링크를 이용하여 웹 페이지를 탐색하고, 내용을 기록하고, 기존에 사용한 Knowledge Refinement 방법을 이용하여, external knowledge라 불리는 관련 web 지식을 불러옵니다. 이러한 corrective 액션은 지식 중 어떤 것도 참조할 수 없는 당황스러운 문제를 극복하는 데 도움을 줍니다.
- Ambiguous
위 두 상황을 제외하고 남은 액션이 Ambiguous입니다. Retriever evaluator가 판단에 확신이 없기 때문에, Correct와 Incorrect에서 처리된 지식 유형 모두 서로 결합됩니다.
아래는 Inference 시의 CRAG 알고리즘을 나타냅니다.

Experiments
RAG 기반 접근방식들과 비교하여 CRAG의 적응력을 비교하고, short and long-form 생성 태스크 모두에서 CRAG의 일반화 능력을 확인하기 위한 실험을 수행했습니다.
Task, Datasets, Metrics
- PopQA (short-form generation)
- Biography (long-form generation)
- PubHealth (true-of-false question)
- Arc-Challenge (multiple-choice question)
PopQA, PubHealth, Arc-Challenge 데이터셋에서는 accuracy metrics를 사용했고, Biography 데이터셋에는 FactScore metrics가 사용됐습니다. (*FactScore: long-form generation에서 factual precision을 자동평가하는 프레임워크)
Baselines
CRAG를 검색하지 않은 방식과 검색한 방식 모두와 비교했고, 검색한 방식은 standard RAG와 advanced RAG로 구성되어 있습니다.
Baselines without retrieval
- LLaMA2-7B, 13B (Public LLMs)
- Alpaca-7B, 13B (Instruction-tuned)
- $CoVE_{65B}$ (Iterative engineering 적용)
- $LLaMA2$-$chat_{13B}$, ChatGPT (Propriety LLMs)
Standard RAG
- LLaMA2-7B, 13B (Public instruction-tuned LLMs)
- Alpaca-7B, 13B
- LLaMA2-7B (Self-RAG에서 instruction-tuned)
Advanced RAG
- SAIL (Instructions 전에 삽입된 top retrieved documents를 가지고 Alpaca instruction-tuning 데이터에 대해 instruction-tuned된 LM)
- Self-RAG (GPT-4로 레이블링된 몇 개의 reflection tokens를 포함하는 instruction-tuning 데이터에 대해 LLaMA2를 tuned)
- Ret-ChatGPT and RetLLaMA-chat (private data로 학습)
- Perplexity.ai (InstructGPT 기반 제품 검색 시스템)
Results
아래 표는 네 개의 데이터셋에 대한 결과입니다. Self-CRAG는 CRAG를 Self-RAG와 결합한 방법입니다.
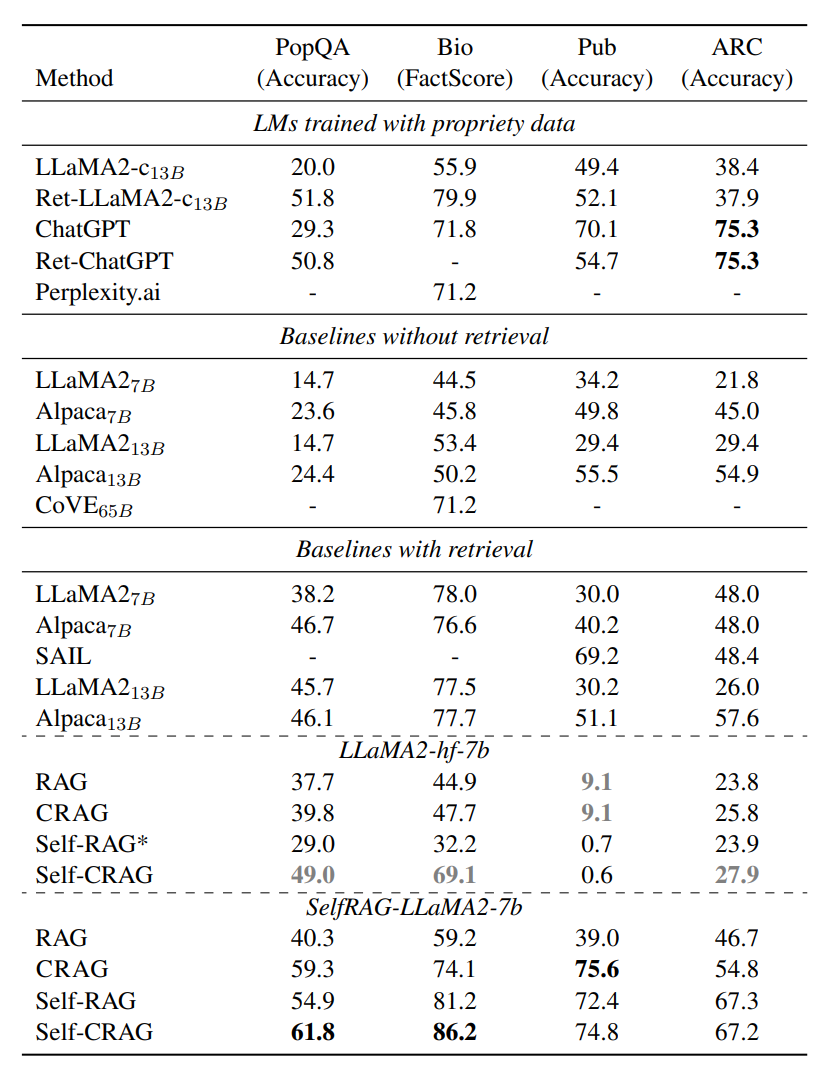
1. 제안된 방법은 RAG와 Self-RAG의 성능을 크게 향상시킬 수 있습니다.
SelfRAG-LLaMA2-7b을 기반으로 할 때, CRAG는 RAG에 비해 PopQA 19.0%, Biography 14.9%, PubHealth 36.6%, Arc-Challenge 8.1% 향상되었을 뿐만 아니라, LLaMA2-hf-7b를 기반으로 할 때, PopQA 2.1%, Biography 2.8%, Arc-Challenge 2.0% 향상되었습니다.
SelfRAG-LLaMA2-7b을 기반으로 할 때, Self-CRAG는 Self-RAG에 비해 PopQA 6.9%, Biography 5.0%, PubHealth 2.4%, 향상되었을 뿐만 아니라, LLaMA2-hf-7b를 기반으로 할 때, PopQA 20.0%, Biography 36.9%, Arc-Challenge 4.0% 향상되었습니다.
본 결과는 RAG 기반 방식에 plug-and-play로 실행될 수 있는 CRAG의 adaptability를 보여줍니다.
2. 제안된 방법은 다양한 생성 태스크에서 뛰어난 일반화 능력을 보여줍니다.
위 표의 벤치마크들은 Short-form entity generation(PopQA), long-form generation (Biography), closed-set tasks(PubHealth, Arc-Challenge) 의 각각 다른 시나리오를 나타냅니다. 이러한 결과는 CRAG의 일관적인 성능을 증명해줍니다.
3. 제안된 방법은 LLM generator을 대체하는 데 있어서 뛰어난 유연성을 보여줍니다.
기본 LLM이 SelfRAG-LLaMA2-7b에서 LLaMA2-hf-7b으로 바뀔 때, CRAG는 여전히 좋은 성능을 보여줍니다. 반면에 Self-RAG의 성능은 몇몇 벤치마크에서는 심지어 standard RAG보다도 상당히 떨어지는 성능을 보여줍니다. 이러한 결과가 발생하는 이유는 필요에 따라 special critic tokens를 출력하는 방법을 배우기 위해, 사람 또는 LLM이 주석을 단 데이터를 사용하여 Self-RAG를 instruction-tuning 해야 하지만, 이 기능은 일반적인 LLM에서는 학습되지 않기 때문입니다. CRAG에는 이러한 기능에 대한 요구 사항이 없습니다. 좀 더 나아가 생각해보면, 향후 더 고급 LLM을 사용할 수 있을 때 CRAG와 쉽게 결합할 수 있는 반면, Self-RAG에는 추가 instruction-tuning이 여전히 필요합니다.
Ablation Study
The impact of each triggered action
PopQA 데이터셋에 대해 각 single action을 제거했을 때의 accuracy를 확인함으로써, triggered action의 영향을 검증합니다. 아래 결과를 보면 어떤 액션을 제거하더라도 성능 저하가 있음을 알 수 있습니다. 이는 각 액션이 generation의 robustness를 향상시키는 것을 보여줍니다.
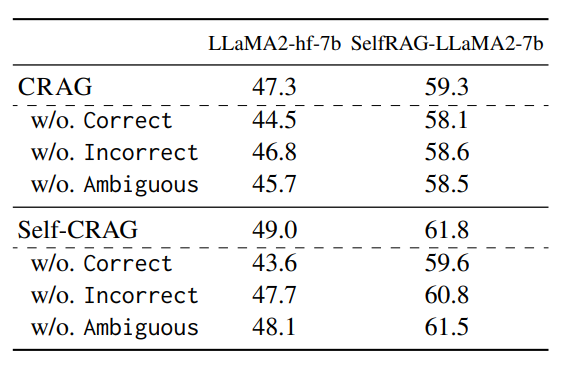
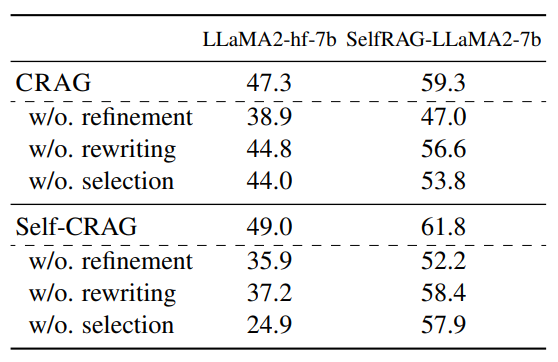
The impact of each knowledge utilization operation
PopQA 데이터셋에 대해 각 knowledge utilization operation을 제거했을 때의 accuracy를 확인함으로써, knowledge utilization operation의 영향을 검증합니다. Refinement를 제거했을 때는 기존 태스크들과 마찬가지로 검색된 원본 문서가 generator에 직접 전달되는 것입니다. 또한 rewriting을 제거했을 때는 지식 검색 중에 질문이 키워드로 구성된 쿼리로 다시 작성되지 않은 것입니다. 마지막으로 selection을 제거했을 때는 웹 페이지의 모든 검색된 내용이 선택 없이 모두 external knowledge로 간주되었음을 나타냅니다. 이는 knowledge utilization operation이 최종 시스템의 성능을 향상시키는 것을 보여줍니다.
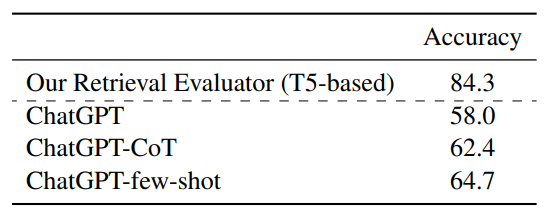
Accuracy of the Retrieval Evaluator
Retrieval Evaluator의 품질은 전체 시스템의 성능에 아주 큰 영향을 미칩니다. 따라서 문서 검색 결과를 바탕으로 Retriever Evaluator가 이러한 결과의 전반적인 품질을 정확하게 결정할 수 있는 지 평가합니다. 결과는 lightweight T5-based retrieval evaluator가 모든 세팅에서 ChatGPT를 크게 능가하는 것으로 보입니다.
Robustness to Retrieval Performance
검색 성능에 대한 robustness를 검증하기 위해, 서로 다른 검색 성능에 따라 생성 성능이 어떻게 변화했는 지를 실험합니다. 정확한 검색 결과의 일부를 의도적으로 무작위로 제거하여 저품질 retriever를 모방하고 성능이 어떻게 변화하는 지 평가합니다. 검색 성능이 떨어짐에 따라 Self-RAG와 Self-CRAG의 생성 성능이 저하됨을 알 수 있으며, 이는 generator가 retriever의 품질에 크게 의존함을 나타냅니다. 또한 검색 성능이 저하됨에 따라 Self-CRAG의 생성 성능이 Self-RAG보다 약간 더 떨어졌습니다.
검색 성능에 대한 robustness를 검증하기 위해, 서로 다른 검색 성능에 따라 생성 성능이 어떻게 변화했는 지를 실험합니다. 정확한 검색 결과의 일부를 의도적으로 무작위로 제거하여 저품질 retriever를 모방하고 성능이 어떻게 변화하는 지 평가합니다. 검색 성능이 떨어짐에 따라 Self-RAG와 Self-CRAG의 생성 성능이 저하됨을 알 수 있으며, 이는 generator가 retriever의 품질에 크게 의존함을 나타냅니다. 또한 검색 성능이 저하됨에 따라 Self-CRAG의 생성 성능이 Self-RAG보다 약간 더 떨어졌습니다. 이러한 결과는 검색 성능에 대한 robustness를 향상시키는 데 있어서 Self-CRAG가 Self-RAG보다 우수함을 의미합니다.

Conclusion
본 논문에서는 RAG의 robustness를 향상시키기 위해 Corrective RAG를 제안합니다. 기본적으로는 retrieval evaluator가 세 가지 액션을 차별적으로 추정하고 트리거합니다. 또한 web search와 최적화된 지식 활용을 더욱 활용함으로써 CRAG는 검색된 문서의 자동 수정 및 활용 능력을 향상시켰습니다.