ICLR 2023 [paper]
Shibo Hao et al.
2 Jun 2023
Introduction

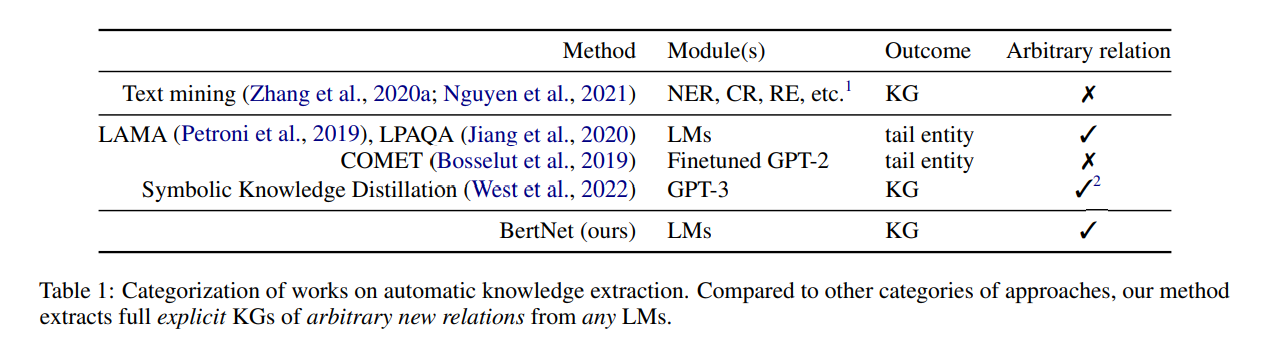
Knowledge Graphs(KGs)는 개체-관계-개체의 정보를 담고 있는 유용한 구조이다. 개체 간 구조를 정의하기 위해 전통적인 방법인 텍스트 마이닝 방법이 제안되었었다. 이러한 방법은 훈련 데이터에 포함된 미리 정의된 관계 집합만 인식할 수 있기 때문에 제한적이다. 이후 방법으로 Pretrained LM을 활용한 Knowledge graph construction 방법이 제안되었다. 이 방법은 ("오바마는 ___에서 태어났다." 빈 칸에 들어갈 말은 "하와이") 와 같은 임의의 프롬프트를 LMs에 querying하는 방법이다. 그러나 이러한 내제적인 쿼리 기반 지식은 KGs의 접근 용이성, 쉬운 브라우징 및 편집 등과 같은 장점들을 활용하지 못한다.
이 논문에서는 Pretrained LMs을 활용하여 임의의 relation에 대한 대규모 KGs를 수집하는 새로운 방법을 제안한다. 프롬프트와 개체 쌍에 대한 few-shot 예시를 포함한 사용자 입력이 주어지면, LM 내에서 자동으로 검색하여 relation에 대한 고품질 Knowledge set을 추출한다. 방대한 개체 쌍 공간에서 효율적으로 검색하기 위해서 효과적인 검색 및 복원 메커니즘을 제안하였다. 또한 이전의 prompt paraphrasing mechanism을 적용하고 prompt weighting을 위해 점수를 다시 매기는 새로운 전략을 통해 일관되고 정확한 결과 knowledge를 도출한다.
그리고 이 논문에서는 ROBERTA, BERT, DISTILBERT와 같은 다양한 LMs을 적용하였다. 이 모델들에 "A는 B를 할 수 있지만 잘하지는 못합니다" 같은 복잡한 관계나 "A는 C에서 B를 할 수 있습니다" 같은 3중 관계에 대해 자동화된 평가를 하면서 다양하고 정확한 KGs을 성공적으로 추출하였다.
Harvesting KGs from LMs
KGs는 < HEAD ENTITY(h), RELATION(r), TAIL ENTITY(t) > 형태의 Knowledge tuples 집합으로 구성된다.기존의 LM 탐색 방법은 head entity와 relation이 주어지면 단일 entity 혹은 소수의 유효한 tail entity를 예측하는 반면에, 제안된 프레임워크는 LM을 활용하여 주어진 모든 관계 r에 대해서 적절한 개체 쌍 (h1, t1), (h2, t2), ... , 을 자동으로 수집한다.
아래 그림 2의 "potential risk"와 같은 관계에 대한 knowledge tuple을 추출하기 위해서, 관계를 정의하는 최소한의 입력만이 요구된다. 이 입력은 "The potential risk of A is B" 같은 초기 프롬프트와 < EATING CANDY, TOOTH DECAY > 같은 몇 개의 개체 쌍 예시들을 포함한다. 여기서 프롬프트는 관계에 대한 전반적인 의미를 제공하고, 개체 쌍 예시는 모호한 부분을 명확하게 한다.
이 프레임워크의 핵심 요소는 confidence weights를 가지고 다양한 프롬프트들을 자동으로 생성하는 모듈과, KGs를 구성하는 일관적인 개체 쌍을 찾기 위한 효율적인 탐색 모듈이 있다. 이에 대해 아래에서 자세히 설명한다.
Creating Diverse Weighted Prompts
이 프레임워크는 초기 프롬프트와 몇 개의 개체 쌍들을 가지고, 의미적으로는 일관되지만 언어적으로는 다양한 프롬프트 세트들을 생성하여 관계를 나타낸다. 위에서 일부 언급했듯, 관계에 대한 다양한 프롬프트를 생성하기 위해 예제 집합에서 개체 쌍을 무작위로 선택하고 이를 초기 프롬프트에 삽입하여 전체 문장을 만든다. 그런 다음 이 문장은 동일한 의미의 여러 개의 병렬 문장을 생성하는 모델에 전달된다. 개체 이름들을 제거하면 각 병렬 문장이 원하는 관계를 설명하는 새로운 프롬프트가 생성된다. 관계의 표현 범위를 넓히기 위해 edit distance 측면에서 서로 다른 프롬프트만 유지시킨다. 이 프로세스는 관계에 대한 프롬프트가 최소 10개가 수집될 때까지 병렬로 변환하여 반복한다.
프롬프트를 자동으로 생성하면 의도한 관계를 정확하게 전달하지 못하는 프롬프트가 생성될 수도 있다. 이를 완화하기 위해, 이후 knowledge search 단계에서의 각 프롬프트의 영향력을 보정하기 위한 지표인 호환성 점수를 활용하는 reweighting method를 제안한다. 특히 각 개체와 개체 쌍 전체를 모두 고려하여 LM 내에서의 프롬프트의 likelihood를 측정함으로써, 개체 쌍과 생성된 프롬프트의 호환성을 평가한다. 이를 통해 각 프롬프트에 대한 적절한 가중치를 결정하고 knowledge search 프로세스의 precision을 향상시킬 수 있다. 개체 쌍 (h, t)와 프롬프트 p 간의 호환성 점수는 아래와 같은 공식으로 나타낼 수 있다.
위 식에서 첫 번째 항은 LM 분포 PLM 내에서의 joint log-likelihood이고, 두 번째 항은 프롬프트(그리고 다른 개체)가 주어진 minimum individual log-likelihood이며, a는 밸런싱 인자(실험에서 a=2/3)이다. 모든 개체 쌍에 대해 생성된 프롬프트의 평균 호환성 점수를 계산한 다음, 프롬프트의 가중치는 모든 프롬프트에 대한 소프트맥스 정규화 점수로 정의된다.
Efficient Search for Consistent Knowledge
위에서 얻은 프롬프트 세트와 해당 confience weights를 가지고, 모든 프롬프트와 일관되게 일치하는 개체 쌍을 검색한다. 검색 프로세스를 안내하고 검색된 개체 쌍의 호환성을 평가하기 위해 위에 정의한 프롬프트 / 개체 쌍 호환성 함수를 재사용하고, 일관성을 다양한 프롬프트와의 호환성의 가중 평균으로 직관적으로 정의하였다.
여기서 wp는 프롬프트 가중치이고 합계는 위와 같이 자동으로 생성된 모든 프롬프트에 대한 것이므로, 모든 프롬프트와 호환되는 개체 쌍은 일관된 것으로 간주한다.
일관성 함수를 기반으로 일관적인 개체 쌍을 검색하기 위한 효율적인 검색 전략을 제안한다. 간단한 접근 방식으로는 모든 개체 쌍을 나열하고, 각 일관성 점수를 계산하고, 결과로 가장 높은 점수를 가진 상위 k개의 개체 쌍을 선택할 수 있다. 그러나 이 접근 방식은 시간 복잡도가 급격하게 높아질 수 있다. 따라서 이를 효율적으로 하기 위해서, 먼저 다양한 프롬프트에 걸쳐 가중평균된 개별 minimum log-likelihood을 사용하여 후보 개체 쌍의 대규모셋을 제안한다. Minimum log-likelihood를 사용하면 모든 검색 단계에서 heap을 유지하고 상위 k개 외의 개체들을 제거하는 등의 가지치기 전략을 사용할 수 있다. 여러 후보를 수집한 후에는 일관성 점수를 활용하여 순위를 다시 매기고 상위 k개의 인스턴스를 출력 knowledge로 선택한다.
Generalization to complex relations
복잡한 관계에 대한 knowledge를 추출하기 위해서 두 가지 경우를 탐색했다.
(1) "A는 B를 할 수 있지만 잘하지는 못한다."
위와 같이 구체적이고 정교한 의미를 가진 관계는 인간이 대규모로 기록하기가 어렵다. 논문에서의 자동화 접근 방식은 초기 프롬프트와 쉽게 수집할 수 있는 몇 가지의 예시 개체 쌍(e.g. <DOG, SWIM>, <CHICKEN, FLY> 등)만 주어지면 이러한 종류의 지식을 자연스럽게 수집할 수 있도록 지원한다.
(2) "A는 C에서 B를 할 수 있다."
위와 같이 두 개 이상의 개체를 포함하는 N-ary 관계를 수용하기 위해 호환성 점수 및 검색 전략을 일반화하여 N-ary 관계를 처리하도록 직접 확장할 수 있다.
Symbolic interpolation of neural LMs
LM에 의해 다양한 프롬프트에서 일관적으로 인식되는, 수확된 지식 튜플은 세상에 대한 LM의 기본 "belief"로 간주될 수 있다. 이렇게 완전히 상징적이고 해석 가능한 튜플은 블랙박스 LM의 지식 기능을 쉽게 탐색하고 분석할 수 있는 수단을 제공한다. 즉, 출력된 KGs를 통해 모델 크기 및 pretraining 전략 등과 같은 다양한 영향들을 이해하기 위해 서로 다른 LM을 비교할 수 있다.
Experiments
프레임워크를 평가하기 위해 다양한 언어모델로부터 다양한 relations에 대한 knowledge를 추출하고 인간 평가를 수행한다. 그런 다음 프레임워크에서 prompt completion 및 scoring function을 더 심층적으로 분석한다. 마지막으로 언어 모델에 저장된 지식을 해석하는 도구로서 프레임워크를 활용하여 블랙박스 모델의 knowledge capacity와 관련된 주목할 만한 관찰을 제공한다.
Setup
Relations
여러 relation sets를 활용하여 프레임워크를 평가한다.
- ConceptNet (Speer et al., 2017)
KG를 필터링하고 20개의 Relations 세트를 사용한다. (e.g. HAS_SUBEVENT, MOTIVATED_BY_GOAL)
이러한 relations에 대한 초기 프롬프트는 ConceptNet 저장소에서 가져온 것이며, 각 relation에 대해 ConceptNet KG에서 5개의 개체 쌍을 무작위로 샘플링한다. - LAMA (Petroni et al., 2019)
T-REx split을 사용한다. (capital_of, member_of 와 같은 WikiPedia 기반 41개 relations)
각 relation에 대해 5개의 개체 쌍을 무작위로 샘플링한다. - Human
기존 KG에서는 찾기 어려운 저자들이 직접 작성한 12개의 relations 세트이다.
각 relation에 대해 초기 프롬프트와 5개의 개체 쌍을 수동으로 작성한다. - Auto
기존 KG나 사람이 작성한 relations 이외에도, 아날로그 추론을 위한 데이터셋인 E-KAR에서 대규모 relation sets을 자동으로 도출한다. 원래 데이터셋에서 개체 쌍 <ID_CARD, IDENTITY>가 주어지면 여러 개체 쌍들 중에서 (e.g. <PRACTICE LICENSE, QUALIFICATION>) 유사한 튜플을 선택하는 것이다. E-KAR에서 샘플을 relation으로 변환하기 위해 질문의 tuple과 올바른 선택을 2-shot 개체 쌍으로 사용하고, E-KAR에서 제공받은 설명으로부터 초기 프롬프트를 추출하여 487개의 relations를 만든다.
Extracting Knowledge of Diverse New Relations
이 프레임워크는 ConceptNet, Auto, Human의 relations를 가지고 LMs으로부터 knowledge graph를 추출하는 데에 사용된다. 그런 다음 추출된 knowledge의 정확도는 Amazon Mechanical Turk(MTURK)를 사용하여 사람의 주석을 통해 평가된다. 추출된 각 knowledge tuple은 True/False/Unjudgable 판사를 사용하여 세 명의 주석자가 정확성에 대해 레이블을 지정한다. Tuple은 두 명 이상의 주석자가 진짜 knowledge로 간주하는 경우 "accepted"로 간주되고, 두 명 이상의 주석자가 거짓으로 평가하는 경우 "rejected"로 간주된다. 여기서 accepted tuples의 일부를 정확도로 지칭한다.
결과 KGs의 통계는 아래 표 2에 나열되어 있다. 이외에, KG 생성을 위한 다른 방법들의 결과도 제시하였다. 다른 방법들의 결과는 설정이 크게 다르기 때문에 일반적으로 직접 비교하기는 어렵다. 단지, 참고 목적으로 결과를 함께 수집하였다. Relation set "Auto"가 있는 RoBERTaNet에서 수집하기 쉬운 487개의 "Auto" relations로 지식을 추출하여 상당히 큰 knowledge sets(122k)를 추출하였다. Relation set은 표에 표시된 것과 같이 ConceptNet을 기반으로 한 KG Completion, Text Mining 모두에서 미리 정의된 relation sets보다 훨씬 큰 규모이다. 65%의 정확도는 COMET(230k) 및 TransOMCS(18.4M)와 비슷한 수준이며, 이는 본 방법이 외부적인 training data없이도 LM을 knowledge의 근원으로서 단독으로 사용하여 새로운 relations를 동적으로 통합할 수 있는 유연성을 제공해야 할 때 합리적이다. 또한 ConceptNet의 relations에서 RobertaNet의 경우, 표에 나열된 숫자가 단순히 비교할 수 있는 것은 아니지만, 동일한 ConceptNet relation sets에서 이미 많은 knowledge terms를 사용하여 fintuned COMET과 비교하여 유사한 정확도와 절대적으로 높은 Novelty를 달성한다는 것을 알 수 있다. 또한 "Human" relation set에 대한 결과는 RobertaNet이 복잡한 relations를 포함해서 매우현실적인 사용자 relations에서 편안하게 작업하고 있음을 나타낸다. 그림 3에서는 DISTILLBERT에서 수집한 knowledge samples를 나타낸다.


Analyzing Automatic Prompt Creation
자동 생성된 프롬프트의 효과를 평가하기 위해, Human relations에 대한 세팅 내에서 생성된 KGs를 비교한다.
(1) Multi-Prompts는 knowledge search에서 자동으로 생성된 다양한 프롬프트를 사용하는 위에서 설명한 전체 프레임워크를 말한다.
(2) Top-1 Prompt는 여러 프롬프트를 앙상블하는 효과를 제거하기 위해, knowledge extraction에 가장 큰 가중치가 있는 프롬프트만 사용하는 변형을 평가한다.
(3) Human Prompt는 자동으로 생성된 프롬프트의 효과를 더 잘 이해하기 위해 각 relation의 초기 프롬프트를 사용하는 변형을 평가한다.
(4) AutoPrompt는 training set에서 tail entity 예측에 대한 likelihood를 최적화함으로써 프롬프트를 학습하도록 제안되었다.
이러한 세팅에 맞추기 위해, 개체 쌍에 대한 호환성 점수(프롬프트 / 개체 쌍 호환성 함수)를 최적화한다.
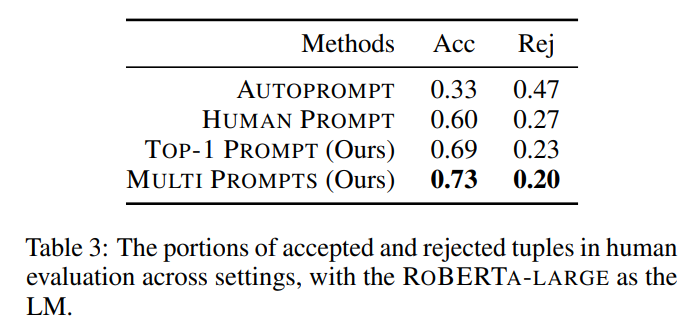
아래의 표 3은 각 Human relation에 대해 1000개의 tuples을 수집하고 human annotation을 사용하여 평가한 결과이다. Top-1 prompt는 Human prompt에 비해 정확도를 최대 9%까지 크게 향상시켜 고품질 프롬프트를 생성하는 데에 있어 프롬프트 검색 알고리즘의 효과를 보여준다. Multi-Prompts는 정확도를 추가로 4% 향상시켜 다양한 프롬프트의 조합이 relation의 의미를 더 잘 포착한다는 것을 나타낸다. 그러나 AutoPrompt에 의해 최적화된 프롬프트를 활용하는 방법은 Human 또는 검색된 프롬프트를 사용하는 것보다 정확도가 낮다. 이는 원하는 relation에 대한 효과적인 프롬프트를 학습하는 데 사용되는 knowledge tuples 수가 충분하지 않아서일 수도 있다.
위 결과를 바탕으로 생성된 프롬프트가 프레임워크에서 scoring 모듈에 어떤 영향을 미치는지 확인하기 위한 실험도 진행하였다. 구체적으로, 프롬프트에 의해 매개변수화된 scoring function의 knowledge accuacy (precision)과 coverage (recall)의 일관성 score를 더 밸런스있게 가져오는지 확인한다. 특정 relation sets로 제한된 다른 scoring 방법과 비교하기 위해, 실험은 ConceptNet 및 LAMA dataset의 기존 용어를 사용하였다.
특히 ConceptNet과 LAMA의 knowledge tuple을 positive samples로 사용하고, true knowledge tuple의 개체들 혹은 관계들을 무작위로 대체하여 동일한 양의 negative samples을 합성한다. 각 scoring function은 높은 점수에서 낮은 점수를 기반으로 샘플의 순위를 매긴다. 그런 다음, 순위를 따라 다른 cut-off points에서 positive samples의 precision과 recall을 모두 계산하고 각 방법에 대한 precision-recall 곡선을 표시한다.
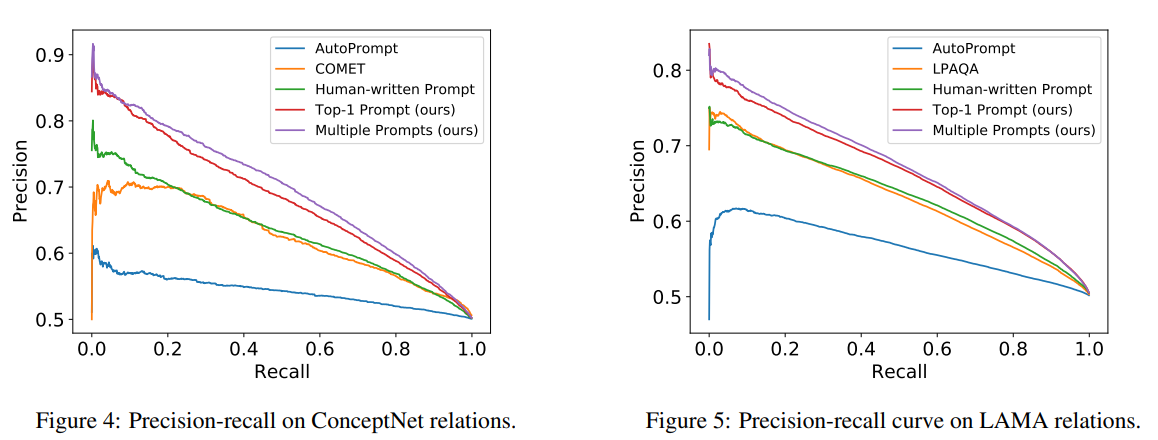
아래 표 1은 주어진 knowledge terms에 대해 자동 평가 설정을 통해 KG completion 및 사실 탐구 와 같은 기존 방식과 비교한 결과이다. (1) COMET은 ConceptNet의 head entity 및 relation (h, r)에 따라 tail entity t를 예측하도록 훈련된 트랜스포머 기반 KG completion 모델이다. (2) LPAQA는 텍스트 마이닝 및 구문 분석을 통해 LAMA에 대한 프롬프트 세트를 수집하고 training sample의 로그 P(t | h, r)를 objective로 하여 가중치를 최적화한다.
ConceptNet 및 LAMA knowledge에 대한 결과 precision-recall 곡선은 각각 그림 4, 그림 5에 나타나있다. Multiple prompts를 사용하여 점수를 매기는 것이 항상 최상의 성능을 달성하고 Top-1 prompt와 Human-written prompt가 잇따른다. 이 결과는 앞서 채점 기능 설계의 효과를 검증한 실험과 일치한다. 본 프레임워크는 ConceptNet의 COMET 및 LAMA의 LPAQA와 같은 다른 기준선도 능가한다. 레이블이 지정된 데이터로 훈련되었지만 이러한 방법은 LM에서 KG을 추출하는 데 필수적인 개체 쌍을 채점하는 대신, 쿼리가 주어지면 tail entity를 완성하는 데만 최적화된다.
Analysis of Knowledge in Different LMs
앞에서 언급했듯이, 결과 Knowledge Graphs는 LM의 상징적인 해석으로 볼 수 있다. 아래 표 4는 5가지 LM에서 Knowledge Graph를 추출하여 human anotation에 제출한 결과이다.
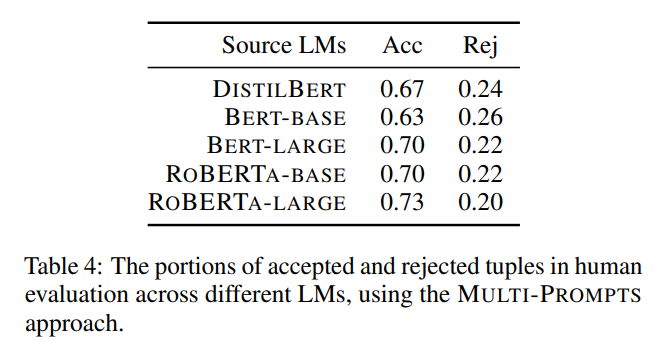
LM이 클수록 더 나은 Knowledge를 인코딩할까?
BERT와 RoBERTa의 큰 버전은 기본 버전과 동일한 pretraining corpus와 tasks를 갖지만, layers(24 vs 12), attention heads(16 vs 12), 파라미터 수(340M, 110M) 측면에서 모델 아키텍처가 더 크다. BertNet-large와 RoBERTaNet-large의 정확도가 각각 기본 버전보다 약 7%, 3% 높은 것을 확인할 수 있으며, 이는 더 큰 모델이 기본 모델보다 실제로 더 나은 Knowledge를 인코딩했음을 나타낸다.
더 나은 사전훈련이 더 나은 Knowledge를 가져올까?
RoBERTa는 BERTa와 동일한 아키텍처를 사용하지만 동적 마스킹, 더 큰 배치 크기 등과 같은 더 나은 사전훈련 전략을 사용한다. 프레임워크의 해당 KG에서 RoBERTaNet-large는 BertNet-large(0.73 vs 0.70)보다 성능이 우수하며, RoBERTaNet-base도 BertNet-base(0.70 vs 0.63)보다 성능이 우수하여 RoBERTa에서 더 나은 사전훈련이 더 나은 Knowledge 학습 및 저장으로 이어진다는 것을 나타낸다.
Knowledge distillation 과정에서 Knowledge가 실제로 유지되는가?
DistillBERT는 BERT-base의 distillation으로 훈련되었고, 매개변수가 40% 감소하였다. 흥미로운 사실은 Knowledge distillation 과정은 knowledge graph의 정확도를 약 4% 향상시킨다. 이것은 교사 모델에서 일부 noisy한 정보를 제거할 수 있는 knowledge distillation 과정에 기여해야만 한다.
Conclusion
본 논문에서는 Pretrained LM(e.g. BERT, ROBERTA)에서 KG를 추출하는 자동 프레임워크를 개발하여 BERTNET, ROBERTANET 등과 같은 새로운 KG 프레임워크를 만들었다. 이 프레임워크는 기존의 Knowledge나 말뭉치의 제한을 받지 않고 임의의 새로운 relation type과 entity에 대한 knowledge를 추출할 수 있다. 또한 결과적으로 KG는 source LMs의 해석적인 역할도 한다.