wandb는 딥러닝 실험 시 사용하면 너무나도 편리한 tool이다. wandb의 기본적인 사용법을 알아보고, pytorch CIFAR10 분류 문제를 wandb를 사용하여 tracking & visualization 해보았다.
wandb란?
딥러닝 실험 과정을 손쉽게 Tracking하고, 시각화할 수 있는 Tool이다. 딥러닝에서 흔히 사용하는 Weights와 Biases을 줄여서 wandb(Weights and biases)라고 부르며, Pytorch, Tensorflow, Keras, Jupyter, Fastai, Scikit 등 다양한 framework를 지원한다.
wandb를 사용하여 아래의 작업들을 수행할 수 있다.
- hyperparameter별 결과 비교
- 학습 과정 visualization
- system 모니터링
- 협업
- 과거 실험 parameter 복제
wandb 초기 설정
1. wandb 회원가입(https://wandb.ai/site)
2. wandb install
pip install wandb3. 로그인
wandb login4. API key 입력(https://app.wandb.ai/authorize)
wandb 명령어
wandb.init()
프로젝트 추적, 로깅 시작
init 함수의 parameter는 생략 가능하며, 그 외 parameter는 wandb documentation(https://docs.wandb.ai/ref/python/init)를 참고하면 된다.
import wandb
wandb.init(project='CIFAR10 Classification Example(Train)')
# 실행 이름 설정
wandb.run.name = 'First wandb'
wandb.run.save()
wandb.config()
hyperparameters를 wandb로 전달
args = {
"learning_rate": learning_rate,
"epochs": epochs,
"batch_size": batch_size
}
wandb.config.update(args)
wandb.log()
출력 결과를 wandb로 전달(dictionary 형식)
wandb.log({"Training loss": running_loss / 2000})
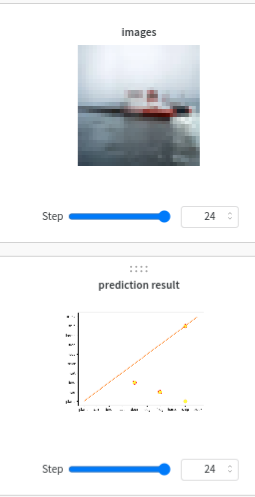
wandb.Image()
이미지를 wandb로 전달
wandb.log({
'images': wandb.Image(images[0]),
'prediction result': wandb.Image(ax)
})
wandb 예제(Train)
pytorch CIFAR10 Classification 튜토리얼(https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html)은 객체를 분류하는 예제이다. 위 예제를 wandb를 사용하여 학습 과정을 tracking & visualization 해보았다.
전체 코드
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import wandb
wandb.init(project='CIFAR10 Classification Example(Train)')
# 실행 이름 설정
wandb.run.name = 'First wandb'
wandb.run.save()
# Hyperparameters
batch_size = 4
learning_rate = 0.001
epochs = 5
args = {
"learning_rate": learning_rate,
"epochs": epochs,
"batch_size": batch_size
}
wandb.config.update(args)
# 1. Load and normalize CIFAR10
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
# 2. Define a CNN
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device:', device)
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net().to(device)
# 3. Define a Loss Function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9)
# 4. Train the network
for epoch in range(epochs): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data[0].to(device), data[1].to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
wandb.log({"Training loss": running_loss / 2000})
running_loss = 0.0
# 모델 weight 저장
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
print('Finished Training')
실행하고 wandb: 🚀 View run at 뒤에 있는 링크를 클릭하면 아래와 같이 loss 값의 변화를 확인할 수 있다.

wandb 예제(Test)
CIFAR10 이미지들을 잘 분류했는지 wandb와 matplotlib를 통해서 결과를 확인해 보았다.
전체 코드
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import wandb
wandb.init(project='CIFAR10 Classification Example(Test)')
# Hyperparameters
batch_size = 4
learning_rate = 0.001
epochs = 5
args = {
"learning_rate": learning_rate,
"epochs": epochs,
"batch_size": batch_size
}
wandb.config.update(args)
# 1. Load and normalize CIFAR10
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
indexes = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 2. Define a CNN
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
PATH = './cifar_net.pth'
net = Net()
net.load_state_dict(torch.load(PATH))
correct = 0
total = 0
# 학습 중이 아니므로, 출력에 대한 변화도를 계산할 필요가 없습니다
with torch.no_grad():
for i, data in enumerate(testloader):
images, labels = data
# 신경망에 이미지를 통과시켜 출력을 계산합니다
outputs = net(images)
# 가장 높은 값(energy)를 갖는 분류(class)를 정답으로 선택하겠습니다
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
if i % 100 == 0:
preds_ = [classes[i] for i in predicted]
labels_ = [classes[i] for i in labels]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(list(predicted),list(labels), marker='o', markersize=10,
markeredgecolor='red', markerfacecolor='yellow', linewidth=2, linestyle='None')
ax.plot(indexes, indexes)
ax.set_xticks(indexes)
ax.set_yticks(indexes)
ax.set_xticklabels(classes)
ax.set_yticklabels(classes)
wandb.log({
'images': wandb.Image(images[0]),
'prediction result': wandb.Image(ax)
})
print(f'Accuracy of the network on the 10000 test images: {100 * correct // total} %')
images에는 입력 이미지가, prediction result에는 예측값(x axis)과 정답(y axis)이 나타난다.