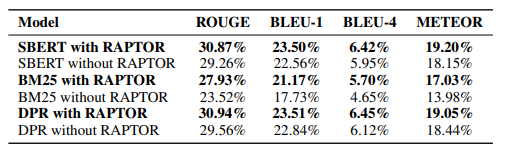
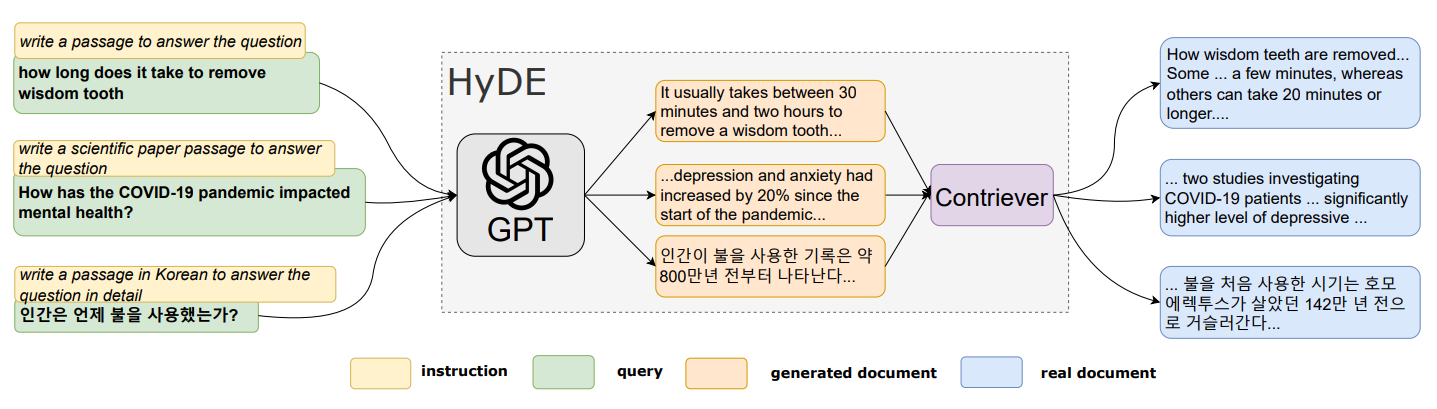
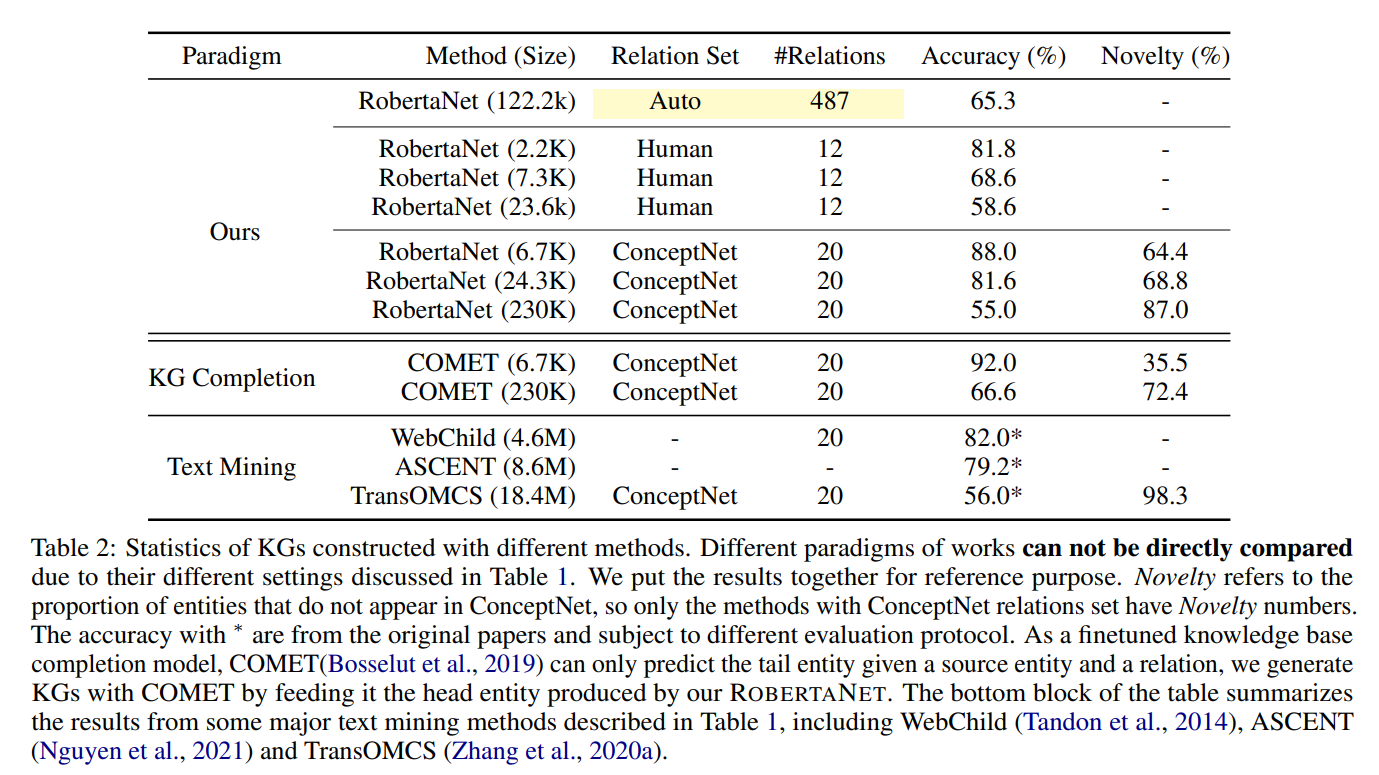
ICLR 2024 [paper]Sarthi et al.31 Jan 2024 IntroductionBackground예시(NarrativeQA dataset)"신데렐라는 어떻게 행복한 결말을 맞이했는가?"기존의 retrieval-augmented 방법들은 연속적인 짧은 청크만 검색하기 때문에 전체 문서 컨텍스트에 대한 이해가 제한된다. 즉, 텍스트의 여러 부분에서 지식을 통합해야 하는 주제와 관련된 질문(위 예시)은 top-k개의 짧고 연속적인 텍스트를 이용하여 질문에 답하기에는 충분한 컨텍스트가 포함되지 않는다.기술의 발전에 따라 모델이 처리할 수 있는 컨텍스트 길이가 확장되면서, "모델에 많은 양의 컨텍스트를 입력해주면 되지 않을까"라는 의문이 제기되었다.그러나 Liu et al. (2023) 과 Su..